

CrowdSignals.io was funded successfully at 134% of our target. To the best of our knowledge this is the first-ever example of a crowdfunded data set. So while the experiment is still ongoing we wanted to share some of our findings from the fund raising campaign!
Backers and Contributions
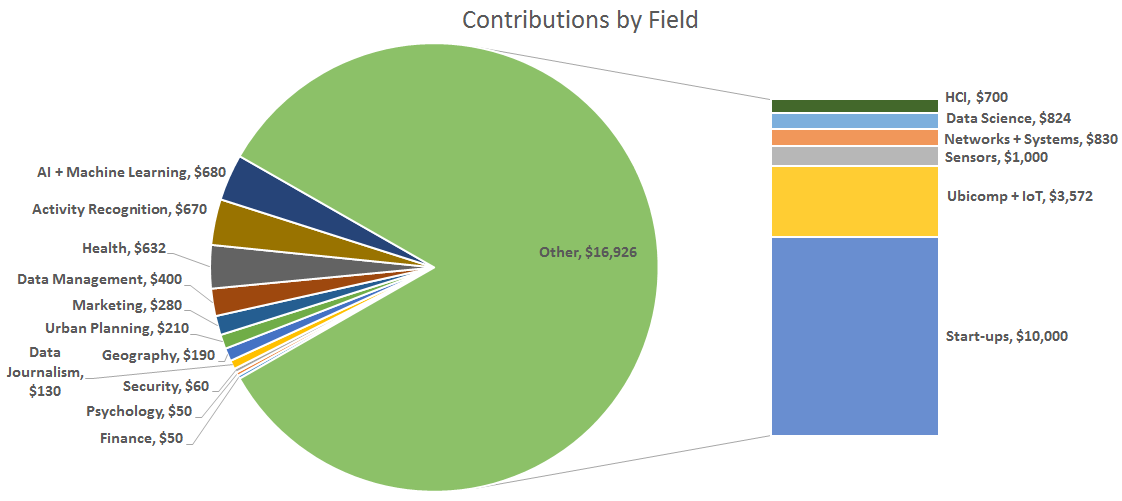
We received support from groups representing several thousand researchers and students globally and across a wide variety of disciplines. While the percentage of funds received from each discipline (see above) in part reflects the communities we marketed to, the New York Times article on CrowdSignals.io attracted support from a much more diverse group. As shown above, a majority of funds came from start-ups that paid to include a custom ground truth label in the CrowdSignals.io data set. Academic and industrial researchers working on the Internet of Things contributed the next largest portion of funding at over $3500 – researcher in Sensors, Data Science, Networks, and HCI formed the next largest segments followed by a variety of other disciplines including Data Journalism, Finance, Psychology, and Urban Planning among others.
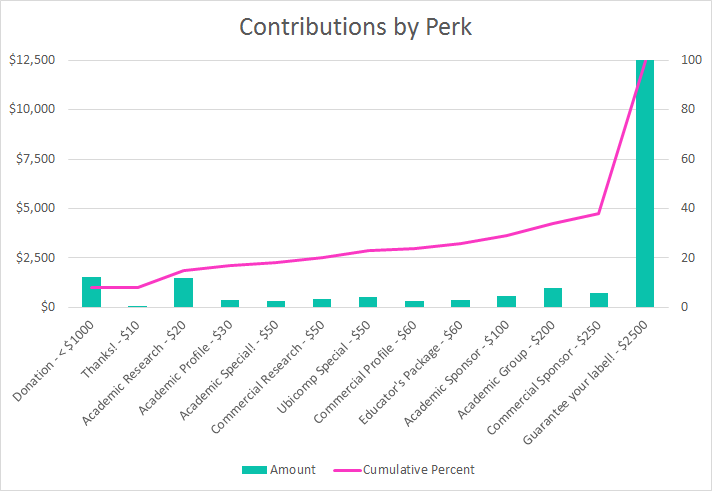
It’s also interesting to note that while the majority of contributions came in small denominations (<=$50) from academic researchers (104 of 158 total contributions), the bulk of funds came from groups that wanted to add their own ground truth label to the data. The chart below shows the distribution of funds received across available Indiegogo perks.
Some Key Insights on Data Crowdfunding
We’ll learn more as we continue the CrowdSignals.io experiment, but several key insights regarding the funding process have emerged. We share them here in case other individuals or institutions are interested in crowdfunded data collection.
- Insight: Institutional approval chains are not a natural match for the excitement and urgency of crowdfunding. Nearly all of our backers are from academic, commercial, or non-profit institutions (very few independent individuals). As such, many needed to obtain institutional approvals to: (1) use funds to purchase data via crowdfunding, and/or (2) use the CrowdSignals.io data for institutional research. For many backers, both (1) and (2) took days or weeks from the time they decided to back CrowdSignals.io to the time the approvals were obtained. We found that for some institutions it was helpful to prepare a customized invoice and data license to accompany the Indiegogo transaction. The CrowdSignals.io “IRB Kit” was also a useful document for academic institutions that needed approval from internal review boards or ethics committees.
- Insight: Researchers and data scientists are busy people and most do not frequent crowdfunding sites – the best way to reach them is direct email, followed by Facebook, then LinkedIn. A majority of our backers are researchers or data scientists at large institutions – all are very busy people, many have overfull inboxes and slow response times when it comes to communication outside their immediate circle of colleagues. It helped to start getting the word out via email and social media about 6 months before the campaign launched. However, a significant effort was required to connect with many backers even immediately before and after launch. The most effective method proved to be personal follow-up emails (sorry if we spammed you! 🙂 ) – over 60% of backers came to our campaign page via an email link. Facebook and LinkedIn were also effective in advertising the campaign to large pre-existing groups (e.g., professional IoT, Machine Learning, and/or Deep Learning groups). We also found that a majority of our backers had never used Indiegogo before.
- Insight: The greatest perceived value is in customization of the data set. As shown above, most of the funds received were for adding a custom ground truth label to the data collection campaign. In this way, several backers were able to customize the data to answer a particular question of interest at their institution. While research has shown that even completely unlabeled data holds significant value (e.g., it can be mined to reveal significant patterns, one stream of data can be used as a label for another), our observation is that customization is critical for a crowdfunded mobile data set. Most researchers backing the project indicated that they were specifically interested in the labels we are collecting or that they would need their own labels in order to make use of the data. This may be different for different types of data (e.g., climate, astronomy), but it does raise the question of whether or not a “one size fits all” data set is actually achievable in this area of research.
We’ll share additional insights as we move forward and would love to hear any feedback you have in the comments below or by email at organizers@crowdsignals.io