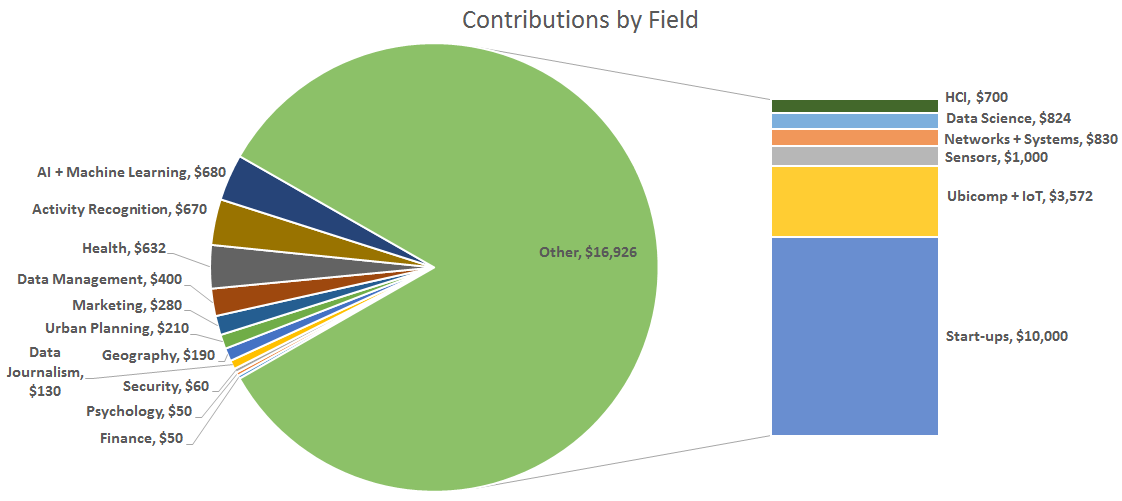
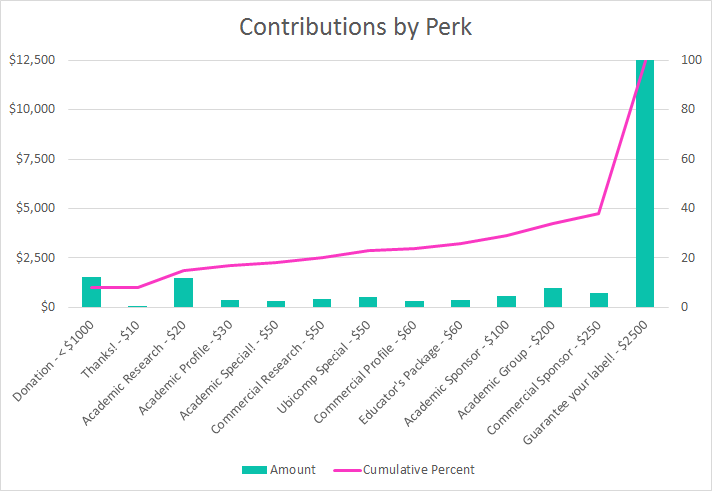
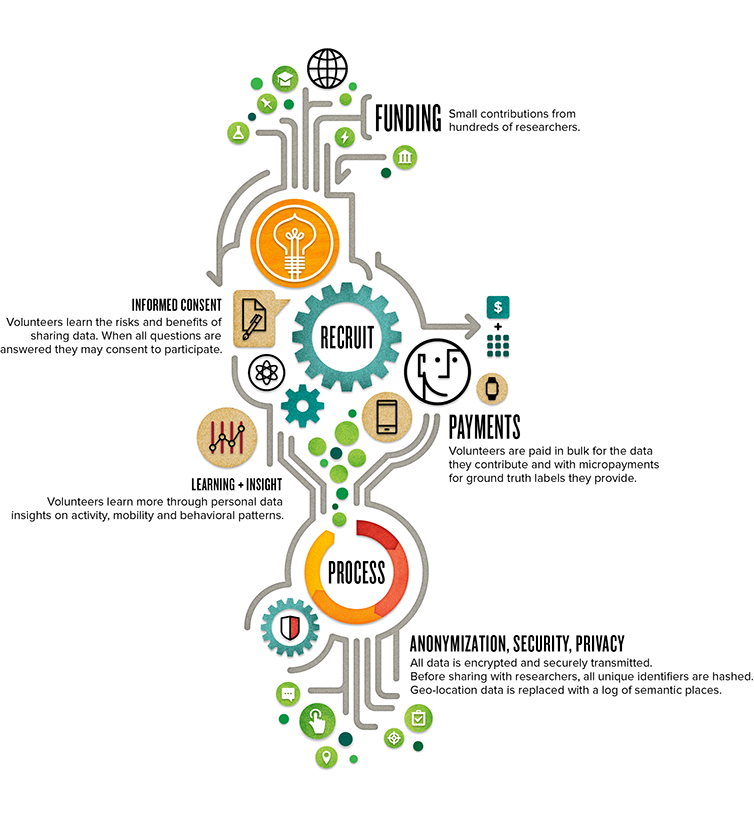
Following discussion with several expert backers, we’re proposing the following labels for ground truth on Places Visited, Contact Relationships, and Sedentary Activities. If you have any feedback, please share it in the comments section or send directly to us at organizers@crowdsignals.io
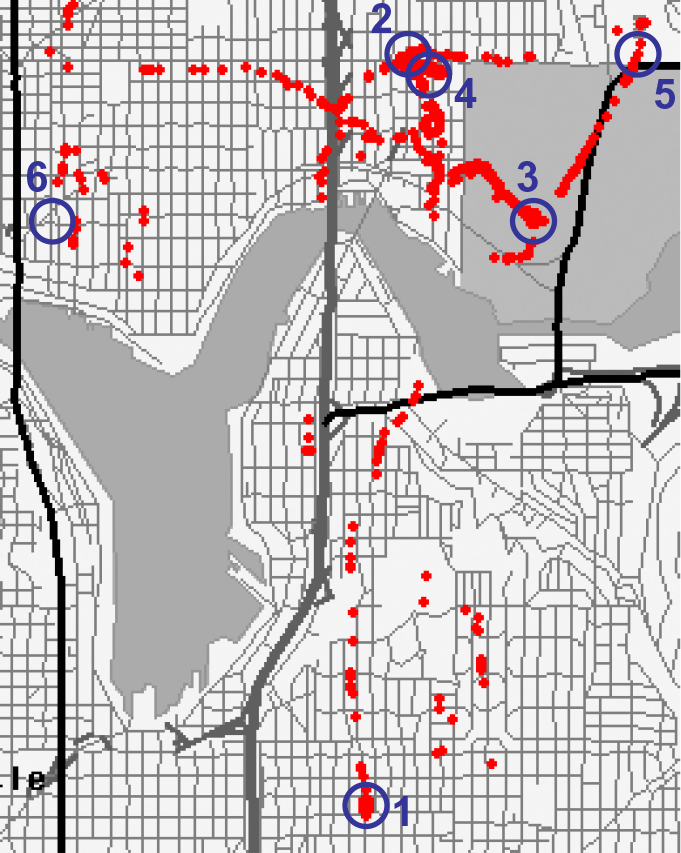
Places Visited
The data on places visited captures a user’s mobility patterns using semantic place categories that do not include any absolute location coordinates. We’re using a relatively standard approach to extraction of significant places from location data (e.g., clustering WLAN, GPS, and GSM data over time). The resulting places are initially tied to a geographic location and one or more visit events that include arrival and departure times. CrowdSignals.io participants will review the (geographically pinned) places on a map and provide one of the following labels for each. The data received by CrowdSignals.io backers will include only place labels with no absolute location information.
| Major Place Category | Minor Place Category |
| Personal | Home, Work, Friend’s house, Family member’s house |
| Automotive | Automobile club, Parking, Car parts, Car rental, Repair service, Car dealership/repair, Car wash, Gas station |
| Business | Bank, Service business, ATM, Convention/Exhibition center, Currency exchange, Manufacturing business |
| Education | University/College, School, Nursery/Pre-school, Elementary school, Middle school, High school |
| Emergency | Pharmacy, General practitioner, Specialist, Dental surgeon/Dentist, Veterinarian, EMS, Fire station, Hospital, Police station |
| Entertainment | Art gallery, Arcade, Casino, Cinema, Museum, Night life/Disco, Stage, Winery |
| Food & Drink | Fast food, Bar, Ice cream, Pizzeria, Restaurant |
| Government | Court house, Embassy, Government office, Prisons |
| Lodging | Camping, Guest house, Hotel, Recreational camp, Youth hostel |
| Other | Travel agency, Cemetery, Others |
| Recreation | Amusement park, Beach, Fairground, National park, National forest, State park, Park, Zoo/Aquarium, Stadium/Arena, Outdoor sport, Bowling alley, Golf course, Ice rink, Sports center, Swimming pool, Tennis court, Marina, Squash court, Pool hall, Others, Hiking ground, Ski resort, Fitness club |
| Public Services | Library, Post office, Tourist information |
| Service Shops | Shopping center, Service shop, Specialty store, Grocery |
| Tourist Attraction | Building, Monument, Mountain, Other tourist attractions, Church |
| Traffic Related | Border post/Frontier crossing, Mountain pass, Rest area |
| Travel | Airline access, Airport, Ferry terminal, Railway station |
Contact Relationships
Contact relationship labels capture the participant-contact relationship category for each anonymous contact communicated with during the data collection period. The proposed labels for use by participants when labeling contact relationships are as follows.
| Contact Category | Contact Relationship |
| Family | Daughter, Son, Mother, Father, Brother, Sister, Aunt, Uncle, Nephew, Niece, Cousin, Grandfather, Grandmother, Grandson, Granddaughter, Mother-in-law, Father-in-law, Brother-in-law, Sister-in-law |
| Romantic | Husband, Wife, Spouse, Domestic Partner, Significant Other |
| Friendship | Best Friend, Friend, Significant Other |
| Organizational | Boss, Employee, Co-Worker, Business Partner, Teacher, Student, Classmate, Religious Leader, Religious Group Member |
| Community | Neighbor, Member of Community Group |
Sedentary Activities
Sedentary activity labels will be collected simply with a two-part lockscreen questionnaire: first, are you seated? Then if so, what are you doing? The second label may take on any of the following values:
| Sedentary Behaviors |
| Eating, In Transit, Hobby, Playing a Game, Reading, Socializing, Using Computer, Watching Television, Working |