Ming Zeng is a Ph.D. student at Carnegie Mellon University. His research interests include machine learning, deep learning, human behavior modeling, and natural language processing. His work is primarily focused on deep neural networks (DNNs) for human activity recognition. The deep learning models used in his work mainly include convolutional neural networks (CNNs) and Long Short Term Memory (LSTM) with different architectures according to different applications. In addition, instead of treating the deep neural network as a black box, he is trying to interpret the features extracted from DNNs.
Ming will explore the CrowdSignals.io data in the human activity recognition related areas. Deep neural networks can take advantage of the large dataset to train a good model. In addition, because the CrowSignals.io dataset involves a number of sensors, it is worth trying neural networks with a sensor fusion approach.
Nima is currently the Viterbi Fellow of Digital Medicine at the Scripps Translational Science Institute, where he is kick-starting new research and engineering efforts related to the use of wearable and passive sensing devices in healthcare. As the first engineer to be working on mHealth related efforts at STSI, he works closely with a team of physicians and statisticians across STSI and the Scripps Health hospital system to develop new technologies that address the needs of patients and physicians. He believes that patient collected data, from outside the clinical setting, will play a major role in ensuring that the future of medical care is both scalable and affordable. Reaching that point will require advances in sensing technologies, user-context recognition, energy-management, and machine learning. His research focuses on the development of new sensing devices (particularly those related to air quality and respiratory health monitoring) and analytical techniques for turning the data collected by phones, wearables, and in-home devices into actionable information for physicians and researchers.
There is a great deal of variance in how individuals interact with technology and the world around them, making the evaluation of context-recognition systems, energy-saving optimizations, and other systems research extremely challenging. The large and diverse CrowdSignals.io dataset, collected by real users in the field, will help us develop more accurate models of how people interact with technology, one another, and the world around them. In particular, the data will be extremely valuable in our dynamic energy-management work, which adjusts sensor and application behavior based on user-context, interaction, and device state.
TwoSense was founded in 2013 by Dawud and Ulf, two researchers in the field of personal data analytics. They saw an imbalance in the quality and quantity of data that was available to large corporations, and the utility that was being offered to users from the majority of businesses they interact with.
They set out to close this gap by creating technology to give the user a data set of their own real-world and digital behavior, and the ability to get value and utility from it.
TwoSense’s mission is give users their personal data, help them get value and utility from it. They give users the tools they need to track themselves effortlessly, and the ability to share what they want with the businesses they interact with in perfect clarity. The result is better data for businesses to deliver value and utility to the user, and more control and transparency for the user.
TwoSen.se is a mobile data analytics company. Their unique experience and expertise allow them to develop and use embedded, hyper-efficient machine learning algorithms for data collection and fusion that run on the device. This approach allows them to reduce power consumption and network usage to a minimum, reducing the cost of ownership to the user. It also provides data availability on mobile in near real-time by cutting out the need for network API turnaround.
They are also experts in processing large data sets using cutting edge analytics algorithms and technologies. Their cloud engines employ deep convolutional networks combined with probabilistic models and methods to combine data across users and applications and create uniquely accurate and effective insight.
By leveraging their expertise and distributing the data processing pipeline across mobile and cloud, TwoSense creates a unique stack for highly-efficient data collection, processing, analysis and insight delivery in real time for our users and customer.
Hiflylabs is a company that provides Business Intelligence, Consulting, and Customer Development services. Based in Budapest, Hungary, they create business value from data. Hifly carries out BI projects in many areas, from data mining and data warehousing to the solution of Big Data problems. To expand their activity, they established a mobile application development department, which has become a reliable element of our skill set. They have extensive experience with the tools of well-known data warehouse and BI technology vendors, and we also use new generation open-source solutions in their projects.
Hiflylabs managing partner, Marton Zimmer.
The core team at Hiflylabs has been working together for 15 years, currently with more than 50 passionate employees: data analysts, data scientists and enthusiastic data ninjas. They have extensive experiences in working and managing multicultural projects and are keen on keeping their exceptional price/performance ratio on all projects.
Hifly will use the CrowdSignals.io data experiment with applying Big Data technology to sensor data, checking performance and usability possibilities.
Rijurekha Sen is a post-doctoral researcher at Max Planck Institute for Software Systems, Germany. She generally works with mobiles and sensors to build applications related to road traffic monitoring, energy measurement and targeted advertising in the retail sector. The technical skills involved in her kind of work are smartphone programming and embedded systems design, sensor data processing using applied machine learning, wireless networking to connect sensors and backend servers and data visualizations on static and interactive maps. There are some logistic skills involved in deploying the systems that she implements, in collaboration with government organizations or startups. Recently, she is working on mobile data privacy to see if cool mobile applications can be supported, even after ensuring data privacy! She is also interested in auditing mobile services and apps created by third parties to measure their functionality and privacy properties as an independent researcher.
She will explore the CrowdSignals.io data primarily in the context of mobile privacy related research. Whether interesting mobile apps can be supported using encrypted data, needs real datasets to be evaluated. She is hoping that the CrowdSignals.io dataset will fill that gap of easily available mobile and sensor data, which can be used to test such research hypotheses or prototype systems.
Our next guest post is by Vinayak Naik, Associate Professor and Founding Coordinator of the MTech in CSE with specialization in Mobile Computing at IIIT-Delhi, New Delhi, India. He writes about his group’s research on using smartphone sensors to measure metro traffic in New Delhi.
In recent years, mobile sensing has been used in myriad of interesting problems that rely on collection of real-time data from various sources. The field of crowd-sourcing or participatory sensing is extensively being used for data collection to find solutions to day-to-day problems. One such problem of growing importance is analytics for smart cities. As per Wikipedia, a smart city is defined as an urban development vision to integrate multiple information and communication technology (ICT) solutions in a secure fashion to manage a city’s assets and notable research is being conducted in this direction. One of the important assets is transportation. With the growing number of people and shrinking land space, it is important to come up with solutions to reduce pollution caused by the vehicles and ease commuting between any two locations within the city.
Today, cities in developed countries, such as New York, London, etc, have millions of bytes of data being logged on a diurnal basis using sensors installed at highway and metro stations. This data is typically leveraged to carry out an extensive analysis to understand usage of roads and metro across the city’s layout and aid in the process of better and uniform city planning in long term. However, a common challenge faced in developing countries is the paucity of such detailed data due to lack of sensors in the infrastructure. In the absence of these statistics, the most credible solution is to collect data via participatory sensing using low-cost sensors like accelerometer, gyroscope, magnetometer, GPS, and WiFi that come packaged with modern day smartphones. These sensors can be used to collect data on behalf of users, which upon analysis can be leveraged in the same way as data made available through infrastructure-based.
Figure 1: (a) and (b) show the relative rush at a given station which aids us in estimating wait time across metro stations. (c) shows a possible Google Maps Utility where an alternate route or transport mode can be suggested depending on the amount.
In short term, this data can be leveraged to guide commuters about expected rush at the stations. This is important as in some extreme cases wait time at stations could be more than the travel time itself. Aged people, those with disabilities, and children can possibly avoid traveling if there is rush at stations. We show two snapshots of platform at Rajiv Chowk metro station in Delhi, in Figure 1(a) and Figure 1(b). These figures show variation in the amount of rush that can happen in a real life scenario. In the long run information from our solution can also be integrated with route planning tools (e.g., Google Maps, see Figure 1(c)), to give an estimated waiting time at the stations. This will help those who want to minimize or avoid waiting at the stations.
About a decade ago, even cities in developed countries had less infrastructural support to get sensory data. The author was the lead integrator of the Personal Environmental Impact Report (PEIR) project in 2008. The objective of the project was to estimate emission and exposure to pollution for the city of Los Angeles [1] in USA. PEIR used data from smartphones to address the problem of lack of data. Today, the same approach is applicable in developing countries, where reach of smartphones is more than that of infrastructure-based sensors. At IIIT-Delhi, master’s student Megha Vij, co-advised by Prof. Viswanath Gunturi and the author, worked her thesis [2] on the problem to build a model, which can predict the metro station activity in the city of New Delhi, India using accelerometer logs collected from a smartphone app.
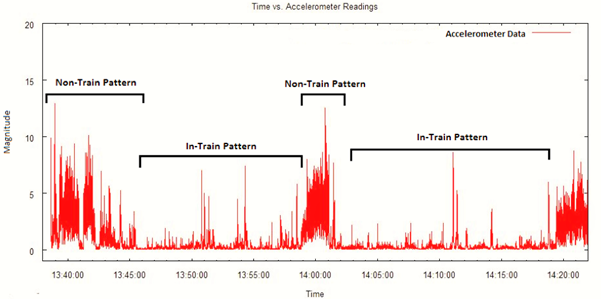
Our approach is to detect commuter’s entry into metro station and thereon measure time spent by the commuter till he/she boards the train. Similarly, we measure the time spent from disembarking the train until exiting the metro station. These two time-durations are indicative of the rush at metro stations, i.e., more the rush, more the time spent. We leverage geo-fencing APIs on the smartphones to detect entry into and exit from the metro stations. These APIs efficiently use GPS to detect whether the user has crossed a boundary, in our case perimeter around the metro station. For detecting boarding and disembarking, we use accelerometers on the smartphones to detect whether the commuter is in a train or not. Unlike geo-fencing, the latter is an unsolved problem. We treat this problem as a two class classification, where the goal is to detect whether a person is traveling in a train or is at the metro station. Furthermore, the “in-metro-station” activity is a collection of many micro-activities including walking, climbing stairs, queuing, etc and therefore, needs to be combined into one single category for the classification. We map this problem to machine learning and explore an array of classification algorithms to solve it. We attempt to use discriminating, both probabilistic and non-probabilistic, classification methods to effectively distinguish such patterns into “in-train” and “in-metro-station” classes.
Figure 2: Sample accelerometer data annotated with the two mobility patterns, “in-train” and “in-station”
Figure 2 illustrates “in-train” and “in-metro-station” classes on sample accelerometer data that we collected. One may observe a stark difference in accelerometer values across the two classes. The values for the”in-train” class have less variance, whereas for the “in-metro-station” class, we observe heavy fluctuations (and thus much greater variance). This was expected since a train typically moves at a uniform speed, whereas in a station we would witness several small activities such as walking, waiting, climbing, sprinting, etc.
It is important to note that this problem is not limited to only analytics for smart cities, e.g., our work is applicable for personal health. Smart bands and watches are used these days to detect users’ activities, such as sitting, walking, and running. At IIIT-Delhi, we are working on these problems. A standardized data collection and sharing app for smartphones would leapfrog our research. CrowdSignals.io fills this need aptly.
Takeshi Okadome is a Professor in the Department of Informatics at Kwansei Gakuin University. His group works on environmental media design, using various sensors to design a new media that represents a physical or “mind” state of a physical object in an environment, and using the media, they create various contents, in particular, web contents together with each person’s favorite objects.
They use sensor network, physical computing, and machine learning technologies to attempt to: (1) to establish a method for interpreting sensor data and verbalizing or visualizing them, (2) to interpolate human actions or real-world events that cannot be directly inferred from sensor data by mining the information on the web, (3) to design “environment media” that represent the verbalized or visualized data, and (4) to create web contents using the environment media. The group also works on recognition of daily living activities from sensor data using machine learning techniques.
Prof. Okadome will use the CrowdSignals.io data to construct better recognition methods for daily living activities using CrowdSignals.io Data and also test the methods using them.
Our second in a series of expert guest posts comes from Bilgin Kosucu, a doctoral student in the WiSe group at Bogazici University Computer Engineering Department. He provides a brief history of their unique and diverse group and writes about their work with wireless sensors and wearables in Turkey.
— Evan
WiSe was established by a computer networks researcher who then extended the work to wireless sensors. Eventually, the research on wireless sensor networks expanded to include wearable/ambient sensors and mobile phones. Currently, we are involved with the analysis of daily activities, ambient assisted living and elderly healthcare including but not limited to the UBI-HEALTH Project, supported by the EC Marie Curie IRSES Program.
As a group we are experienced of designing and developing mobile data collection platforms (e.g. on Android phones and Samsung Galaxy Gear S smartwatches), but we believe that CrowdSignals.io will build a unique database, having dedicated data annotators and considering the immense difficulty of gathering the ground truth data. This database will serve as common platform, owing its popularity to being a crowd funded collaboration, for researchers to test and compare their algorithms.
In addition to the opportunity of applying our previous research of activity recognition to a well defined and standardized dataset, we hope to reach out to the wearable computing community and build the pavement for finer research through advanced collaboration.
Lumme Inc is developing a personalized quit program for smokers by combining wearable sensors, data analytics, and behavioral psychology. They are developing the technology to automate and scale personalized care. With data from a phone and wristband, the Lumme platform can automatically detect when the user is smoking and identify triggers associated with smoking behavior. This information is then used to predict high risk situations and prevent a relapse by offering just-in-time intervention, specifically designed to induce lasting behavioral change. This technology pushes the envelope of traditional therapy to make this the last quit attempt of every smoker.
Abhinav Parate, Head of R&D and Akshaya Shanmugam, Project Manager
With data from CrowdSignals.io, Lumme will test their smoking-detection algorithms and expand the technology to include detection of eating behavior as a possible trigger for smoking behavior. This can further enable our technology to detect and treat eating disorders such as binge-eating disorder, anorexia nervosa, bulimia nervosa, and obesity.
We live in exciting times. In the cognitive sciences, the big news for the last twenty or thirty years has been the ability to look inside the functioning brain in real time. A lot has been learned but, as always, science is hard and progress occurs in fits and starts. A critical piece that has been missing is the ability to characterize the environment in which people operate. In the early 1990s, John Anderson introduced rational analysis, which uses statistical analyses of environmental contingencies in order to understand the structure of cognition. Despite showing early promise, the method was stymied by a lack of technologies to collect the environmental data. Now the situation has changed. Smartphones, watches and other wearables are starting to provide us with access to environmental data at scale. For the first time, we can look at cognition from the inside and outside at the same time. Efforts such as CrowdSignals.io are going to be key to realizing the potential.
As an example of what is possible, I would like to highlight a line of research I have been engaged in with Per Sederberg, Vishnu Sreekumar, Dylan Nielson and Troy Smith, which was published in the Proceedings of the National Academy of Sciences last year.
The story starts with rats. In 2014, the Nobel Prize in Physiology and Medicine was awarded to John O’Keefe, May-Britt Moser and Edvard Moser for their discovery of place and grid cells in the rat hippocampus. Within the medial temporal lobe are cells that fire when a rat is in a given location in a room. The cells are laid out in regular patterns creating a coordinate system. For rats, we are talking about spatial scales of meters and temporal scales of seconds. We were interested in whether the same areas would be involved as people attempted to remember experiences over the much longer spatial and temporal scales on which we operate.
To test the idea, we had people wear a smartphone in a pouch around their necks for 2-4 weeks. The phone captured images, accelerometry, GPS coordinates and audio (obfuscated for privacy) automatically as they engaged in their activities of daily living. Later, we showed them their images and asked them to recall their experiences while we scanned their brains using functional magnetic resonance imaging.
We knew when and where each image had been taken, so we were able to create a matrix of the distances between the images in time and in space. Rather than meters and seconds our distances ranged over kilometers and weeks. We then created similar matrices by examining the pattern of neural activity in each of many small regions across the brain for each image. If the pattern of distances in the neural activity is able to predict the pattern of distances in time and/or space then one can deduce that that region is coding information that is related to time and/or space.
We found that areas at the front (anterior) of the hippocampus coded for both time and space. As with the work by O’Keefe, Moser and Moser, it was the hippocampus and surrounding areas that were implicated. What was different, however, is that the regions that were most strongly implicated were at the front of the hippocampus, rather than towards the back as is usually the case. More work is necessary, but one interesting hypothesis is that the scale of both temporal and spatial representations decreases as one moves along the hippocampus towards the back of the brain. Perhaps as people attempt to isolate specific autobiographical events they start with a broad idea of where the event is in time and space and zoom in on the specific event progressively activating representations along the hippocampus.
Beyond this specific hypothesis, this work demonstrates what one can achieve if one combines neuroimaging techniques with experience sampling technologies like smartphones. No doubt it won’t be long before our current efforts are seen as terribly crude. Nonetheless we have a reached a milestone – a place where two powerful techniques intersect – and I think that bodes well for attacking what is in my opinion the most fascinating challenge of all – understanding the human mind.
Nielson, D. M., Smith, T. A., Sreekumar, V., Dennis, S., & Sederberg, P. B. (2015). Human hippocampus represents space and time during retrieval of real-world memories. Proceedings of the National Academy of Sciences,112(35), 11078-11083.

 Ming Zeng is a Ph.D. student at Carnegie Mellon University. His research interests include machine learning, deep learning, human behavior modeling, and natural language processing. His work is primarily focused on deep neural networks (DNNs) for human activity recognition. The deep learning models used in his work mainly include convolutional neural networks (CNNs) and Long Short Term Memory (LSTM) with different architectures according to different applications. In addition, instead of treating the deep neural network as a black box, he is trying to interpret the features extracted from DNNs.
Ming Zeng is a Ph.D. student at Carnegie Mellon University. His research interests include machine learning, deep learning, human behavior modeling, and natural language processing. His work is primarily focused on deep neural networks (DNNs) for human activity recognition. The deep learning models used in his work mainly include convolutional neural networks (CNNs) and Long Short Term Memory (LSTM) with different architectures according to different applications. In addition, instead of treating the deep neural network as a black box, he is trying to interpret the features extracted from DNNs.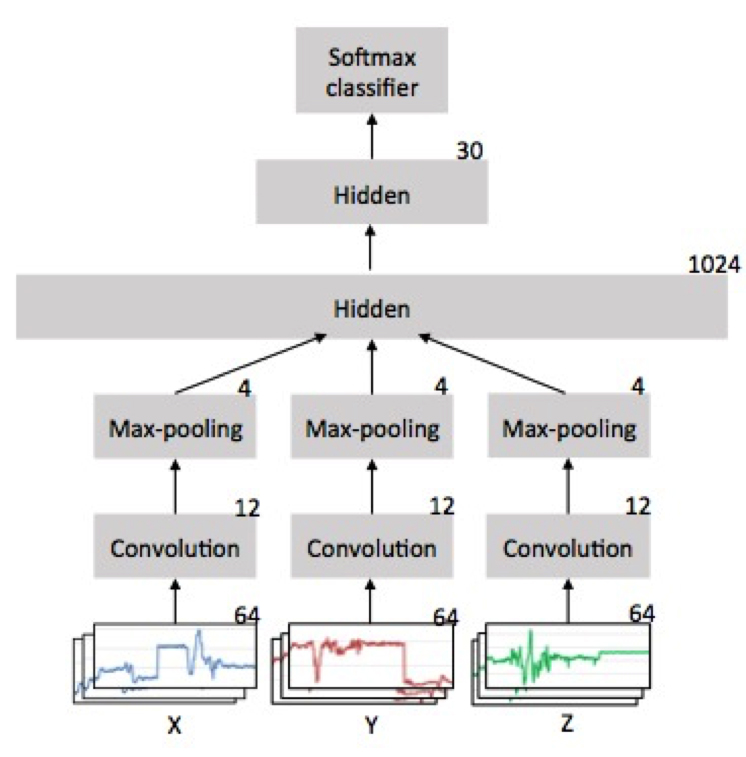
 Nima is currently the Viterbi Fellow of Digital Medicine at the Scripps Translational Science Institute, where he is kick-starting new research and engineering efforts related to the use of wearable and passive sensing devices in healthcare. As the first engineer to be working on mHealth related efforts at STSI, he works closely with a team of physicians and statisticians across STSI and the Scripps Health hospital system to develop new technologies that address the needs of patients and physicians. He believes that patient collected data, from outside the clinical setting, will play a major role in ensuring that the future of medical care is both scalable and affordable. Reaching that point will require advances in sensing technologies, user-context recognition, energy-management, and machine learning. His research focuses on the development of new sensing devices (particularly those related to air quality and respiratory health monitoring) and analytical techniques for turning the data collected by phones, wearables, and in-home devices into actionable information for physicians and researchers.
Nima is currently the Viterbi Fellow of Digital Medicine at the Scripps Translational Science Institute, where he is kick-starting new research and engineering efforts related to the use of wearable and passive sensing devices in healthcare. As the first engineer to be working on mHealth related efforts at STSI, he works closely with a team of physicians and statisticians across STSI and the Scripps Health hospital system to develop new technologies that address the needs of patients and physicians. He believes that patient collected data, from outside the clinical setting, will play a major role in ensuring that the future of medical care is both scalable and affordable. Reaching that point will require advances in sensing technologies, user-context recognition, energy-management, and machine learning. His research focuses on the development of new sensing devices (particularly those related to air quality and respiratory health monitoring) and analytical techniques for turning the data collected by phones, wearables, and in-home devices into actionable information for physicians and researchers. TwoSense was founded in 2013 by Dawud and Ulf, two researchers in the field of personal data analytics. They saw an imbalance in the quality and quantity of data that was available to large corporations, and the utility that was being offered to users from the majority of businesses they interact with.
TwoSense was founded in 2013 by Dawud and Ulf, two researchers in the field of personal data analytics. They saw an imbalance in the quality and quantity of data that was available to large corporations, and the utility that was being offered to users from the majority of businesses they interact with.
 Hiflylabs is a company that provides Business Intelligence, Consulting, and Customer Development services. Based in Budapest, Hungary, they create business value from data. Hifly carries out BI projects in many areas, from data mining and data warehousing to the solution of Big Data problems. To expand their activity, they established a mobile application development department, which has become a reliable element of our skill set. They have extensive experience with the tools of well-known data warehouse and BI technology vendors, and we also use new generation open-source solutions in their projects.
Hiflylabs is a company that provides Business Intelligence, Consulting, and Customer Development services. Based in Budapest, Hungary, they create business value from data. Hifly carries out BI projects in many areas, from data mining and data warehousing to the solution of Big Data problems. To expand their activity, they established a mobile application development department, which has become a reliable element of our skill set. They have extensive experience with the tools of well-known data warehouse and BI technology vendors, and we also use new generation open-source solutions in their projects.
 Rijurekha Sen is a post-doctoral researcher at Max Planck Institute for Software Systems, Germany. She generally works with mobiles and sensors to build applications related to road traffic monitoring, energy measurement and targeted advertising in the retail sector. The technical skills involved in her kind of work are smartphone programming and embedded systems design, sensor data processing using applied machine learning, wireless networking to connect sensors and backend servers and data visualizations on static and interactive maps. There are some logistic skills involved in deploying the systems that she implements, in collaboration with government organizations or startups. Recently, she is working on mobile data privacy to see if cool mobile applications can be supported, even after ensuring data privacy! She is also interested in auditing mobile services and apps created by third parties to measure their functionality and privacy properties as an independent researcher.
Rijurekha Sen is a post-doctoral researcher at Max Planck Institute for Software Systems, Germany. She generally works with mobiles and sensors to build applications related to road traffic monitoring, energy measurement and targeted advertising in the retail sector. The technical skills involved in her kind of work are smartphone programming and embedded systems design, sensor data processing using applied machine learning, wireless networking to connect sensors and backend servers and data visualizations on static and interactive maps. There are some logistic skills involved in deploying the systems that she implements, in collaboration with government organizations or startups. Recently, she is working on mobile data privacy to see if cool mobile applications can be supported, even after ensuring data privacy! She is also interested in auditing mobile services and apps created by third parties to measure their functionality and privacy properties as an independent researcher.
 In recent years, mobile sensing has been used in myriad of interesting problems that rely on collection of real-time data from various sources. The field of crowd-sourcing or participatory sensing is extensively being used for data collection to find solutions to day-to-day problems. One such problem of growing importance is analytics for smart cities. As per Wikipedia, a smart city is defined as an urban development vision to integrate multiple information and communication technology (ICT) solutions in a secure fashion to manage a city’s assets and notable research is being conducted in this direction. One of the important assets is transportation. With the growing number of people and shrinking land space, it is important to come up with solutions to reduce pollution caused by the vehicles and ease commuting between any two locations within the city.
In recent years, mobile sensing has been used in myriad of interesting problems that rely on collection of real-time data from various sources. The field of crowd-sourcing or participatory sensing is extensively being used for data collection to find solutions to day-to-day problems. One such problem of growing importance is analytics for smart cities. As per Wikipedia, a smart city is defined as an urban development vision to integrate multiple information and communication technology (ICT) solutions in a secure fashion to manage a city’s assets and notable research is being conducted in this direction. One of the important assets is transportation. With the growing number of people and shrinking land space, it is important to come up with solutions to reduce pollution caused by the vehicles and ease commuting between any two locations within the city.


 the
the 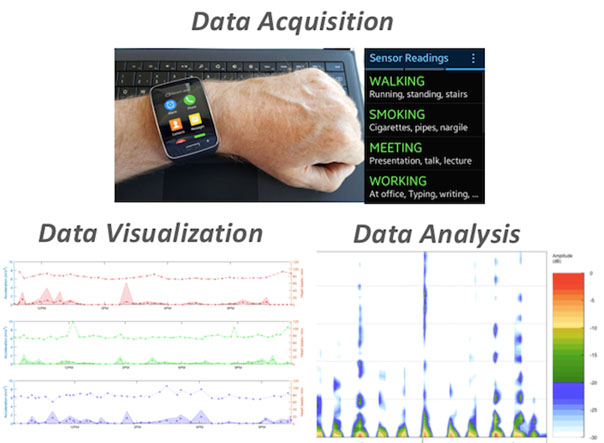

 We live in exciting times. In the cognitive sciences, the big news for the last twenty or thirty years has been the ability to look inside the functioning brain in real time. A lot has been learned but, as always, science is hard and progress occurs in fits and starts. A critical piece that has been missing is the ability to characterize the environment in which people operate. In the early 1990s, John Anderson introduced rational analysis, which uses statistical analyses of environmental contingencies in order to understand the structure of cognition. Despite showing early promise, the method was stymied by a lack of technologies to collect the environmental data. Now the situation has changed. Smartphones, watches and other wearables are starting to provide us with access to environmental data at scale. For the first time, we can look at cognition from the inside and outside at the same time. Efforts such as
We live in exciting times. In the cognitive sciences, the big news for the last twenty or thirty years has been the ability to look inside the functioning brain in real time. A lot has been learned but, as always, science is hard and progress occurs in fits and starts. A critical piece that has been missing is the ability to characterize the environment in which people operate. In the early 1990s, John Anderson introduced rational analysis, which uses statistical analyses of environmental contingencies in order to understand the structure of cognition. Despite showing early promise, the method was stymied by a lack of technologies to collect the environmental data. Now the situation has changed. Smartphones, watches and other wearables are starting to provide us with access to environmental data at scale. For the first time, we can look at cognition from the inside and outside at the same time. Efforts such as