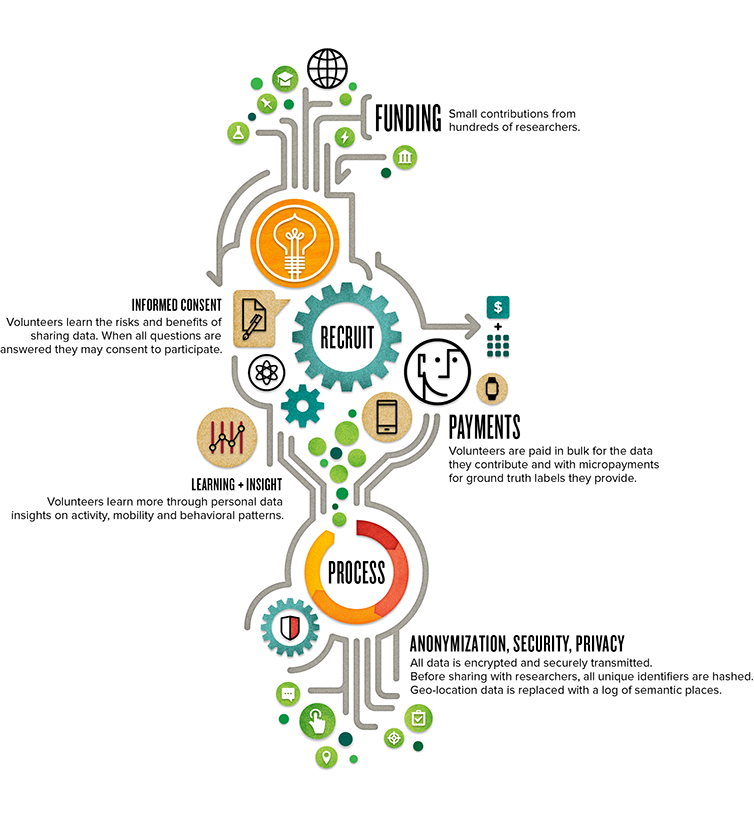
We’re introducing the first in a series of fascinating guest posts from experts who have backed the CrowdSignals.io campaign. Today’s post is from Simon Dennis, Head of the School of Psychology at the University of Newcastle and CEO of Unforgettable Technologies LLC.
— Evan
 We live in exciting times. In the cognitive sciences, the big news for the last twenty or thirty years has been the ability to look inside the functioning brain in real time. A lot has been learned but, as always, science is hard and progress occurs in fits and starts. A critical piece that has been missing is the ability to characterize the environment in which people operate. In the early 1990s, John Anderson introduced rational analysis, which uses statistical analyses of environmental contingencies in order to understand the structure of cognition. Despite showing early promise, the method was stymied by a lack of technologies to collect the environmental data. Now the situation has changed. Smartphones, watches and other wearables are starting to provide us with access to environmental data at scale. For the first time, we can look at cognition from the inside and outside at the same time. Efforts such as CrowdSignals.io are going to be key to realizing the potential.
We live in exciting times. In the cognitive sciences, the big news for the last twenty or thirty years has been the ability to look inside the functioning brain in real time. A lot has been learned but, as always, science is hard and progress occurs in fits and starts. A critical piece that has been missing is the ability to characterize the environment in which people operate. In the early 1990s, John Anderson introduced rational analysis, which uses statistical analyses of environmental contingencies in order to understand the structure of cognition. Despite showing early promise, the method was stymied by a lack of technologies to collect the environmental data. Now the situation has changed. Smartphones, watches and other wearables are starting to provide us with access to environmental data at scale. For the first time, we can look at cognition from the inside and outside at the same time. Efforts such as CrowdSignals.io are going to be key to realizing the potential.
As an example of what is possible, I would like to highlight a line of research I have been engaged in with Per Sederberg, Vishnu Sreekumar, Dylan Nielson and Troy Smith, which was published in the Proceedings of the National Academy of Sciences last year.
The story starts with rats. In 2014, the Nobel Prize in Physiology and Medicine was awarded to John O’Keefe, May-Britt Moser and Edvard Moser for their discovery of place and grid cells in the rat hippocampus. Within the medial temporal lobe are cells that fire when a rat is in a given location in a room. The cells are laid out in regular patterns creating a coordinate system. For rats, we are talking about spatial scales of meters and temporal scales of seconds. We were interested in whether the same areas would be involved as people attempted to remember experiences over the much longer spatial and temporal scales on which we operate.
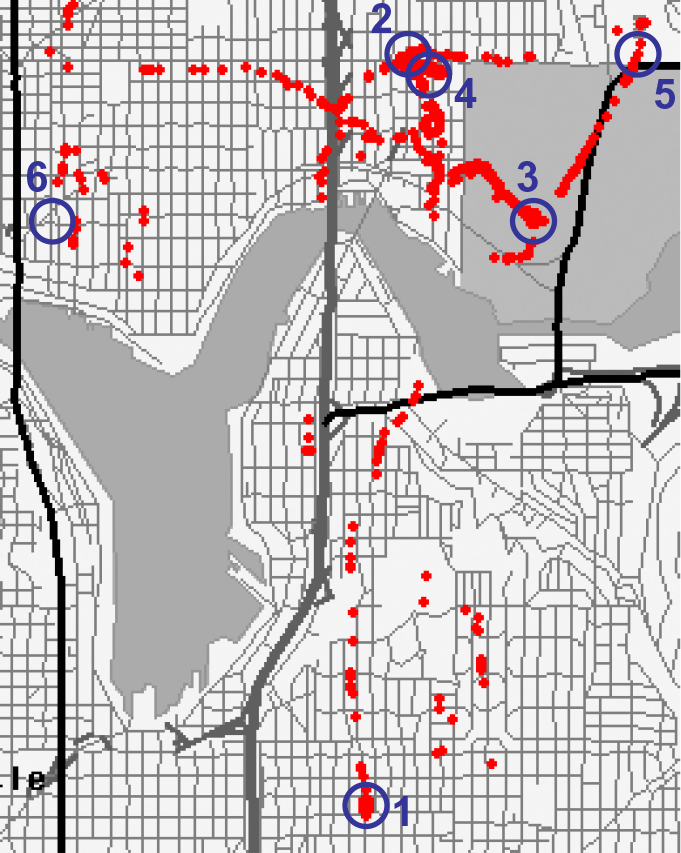
To test the idea, we had people wear a smartphone in a pouch around their necks for 2-4 weeks. The phone captured images, accelerometry, GPS coordinates and audio (obfuscated for privacy) automatically as they engaged in their activities of daily living. Later, we showed them their images and asked them to recall their experiences while we scanned their brains using functional magnetic resonance imaging.
We knew when and where each image had been taken, so we were able to create a matrix of the distances between the images in time and in space. Rather than meters and seconds our distances ranged over kilometers and weeks. We then created similar matrices by examining the pattern of neural activity in each of many small regions across the brain for each image. If the pattern of distances in the neural activity is able to predict the pattern of distances in time and/or space then one can deduce that that region is coding information that is related to time and/or space.
We found that areas at the front (anterior) of the hippocampus coded for both time and space. As with the work by O’Keefe, Moser and Moser, it was the hippocampus and surrounding areas that were implicated. What was different, however, is that the regions that were most strongly implicated were at the front of the hippocampus, rather than towards the back as is usually the case. More work is necessary, but one interesting hypothesis is that the scale of both temporal and spatial representations decreases as one moves along the hippocampus towards the back of the brain. Perhaps as people attempt to isolate specific autobiographical events they start with a broad idea of where the event is in time and space and zoom in on the specific event progressively activating representations along the hippocampus.
Beyond this specific hypothesis, this work demonstrates what one can achieve if one combines neuroimaging techniques with experience sampling technologies like smartphones. No doubt it won’t be long before our current efforts are seen as terribly crude. Nonetheless we have a reached a milestone – a place where two powerful techniques intersect – and I think that bodes well for attacking what is in my opinion the most fascinating challenge of all – understanding the human mind.
Nielson, D. M., Smith, T. A., Sreekumar, V., Dennis, S., & Sederberg, P. B. (2015). Human hippocampus represents space and time during retrieval of real-world memories. Proceedings of the National Academy of Sciences,112(35), 11078-11083.

 Dr. Flora Salim is a Senior Lecturer at the Computer Science and IT department, School of Science, RMIT University. Her research interests are mobile data mining, context-aware computing, activity and behaviour recognition, and context and semantic learning. Her research seeks to enhance user experience by monitoring their behaviours and how they use and interact with their environments, such as in smart home, smart cities, urban transport and mobility, using ambient technologies and ubiquitous computing. Her recent work focuses on analysing and predicting the fine-grained behaviours in human mobility by leveraging heterogeneous sensor data. Previously, she was a Research Fellow at RMIT Spatial Information Architecture Laboratory and an Honorary Research Fellow and Associate Lecturer at Faculty of Information Technology, Monash University. She obtained her PhD in Computer Science from Monash University in 2009. She has secured grants from Australian Research Council, IBM Smarter Cities Lab, Australian Urban Research Infrastructure Network, and numerous industry partners.
Dr. Flora Salim is a Senior Lecturer at the Computer Science and IT department, School of Science, RMIT University. Her research interests are mobile data mining, context-aware computing, activity and behaviour recognition, and context and semantic learning. Her research seeks to enhance user experience by monitoring their behaviours and how they use and interact with their environments, such as in smart home, smart cities, urban transport and mobility, using ambient technologies and ubiquitous computing. Her recent work focuses on analysing and predicting the fine-grained behaviours in human mobility by leveraging heterogeneous sensor data. Previously, she was a Research Fellow at RMIT Spatial Information Architecture Laboratory and an Honorary Research Fellow and Associate Lecturer at Faculty of Information Technology, Monash University. She obtained her PhD in Computer Science from Monash University in 2009. She has secured grants from Australian Research Council, IBM Smarter Cities Lab, Australian Urban Research Infrastructure Network, and numerous industry partners.